How to create a technical staging model
In this section we explain the steps you need to follow to create a technical staging model model (TSM).
- Step 1. Adding an empty model
- Step 2. Creating entities and attributes
- Step 3. Adding metadata
- Step 4.Preparing for delta loads
- Step 5. Adding helpers
- Step 6. Adding computed columns
At any moment, you can perform a model check to verify if there are errors in the model.
Example
We use the TPCH benchmark to illustrate the process of creating a technical staging model. Consider that data will be delivered in several tables as described below
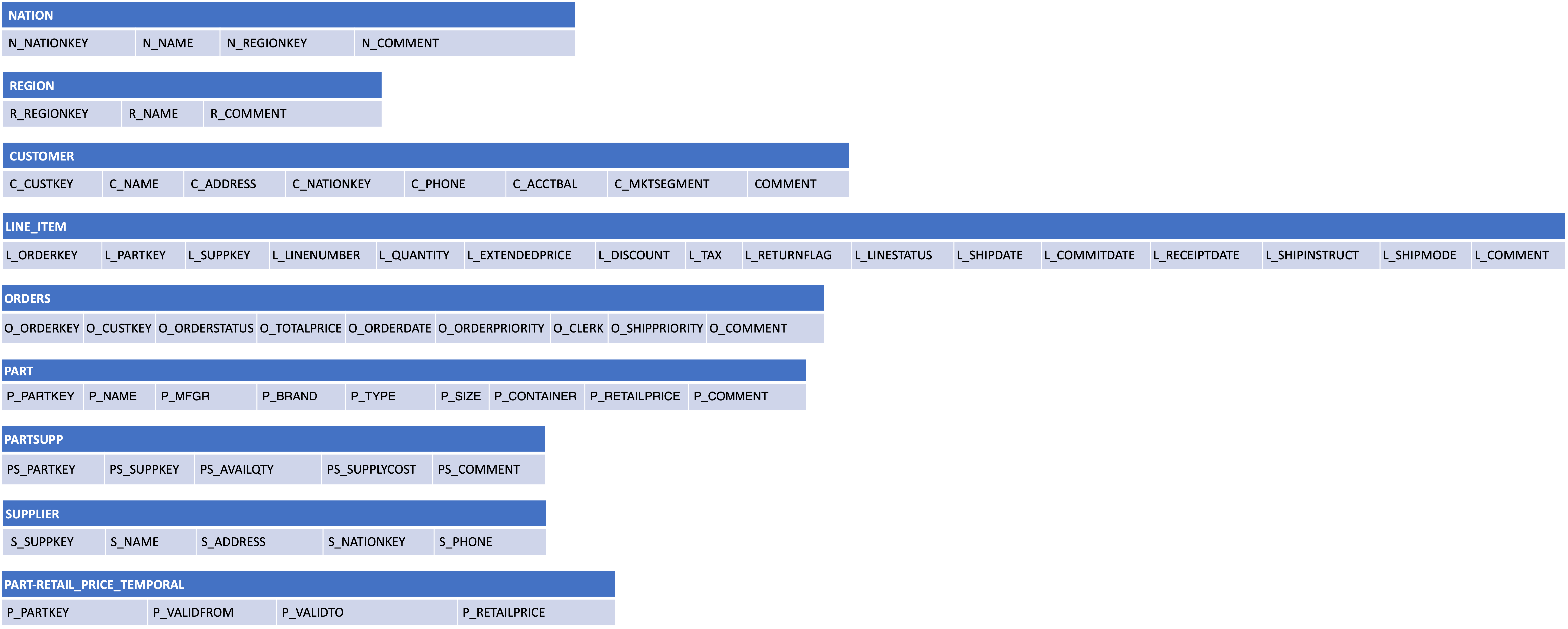
and the business requirements are described in the logical data model presented below.
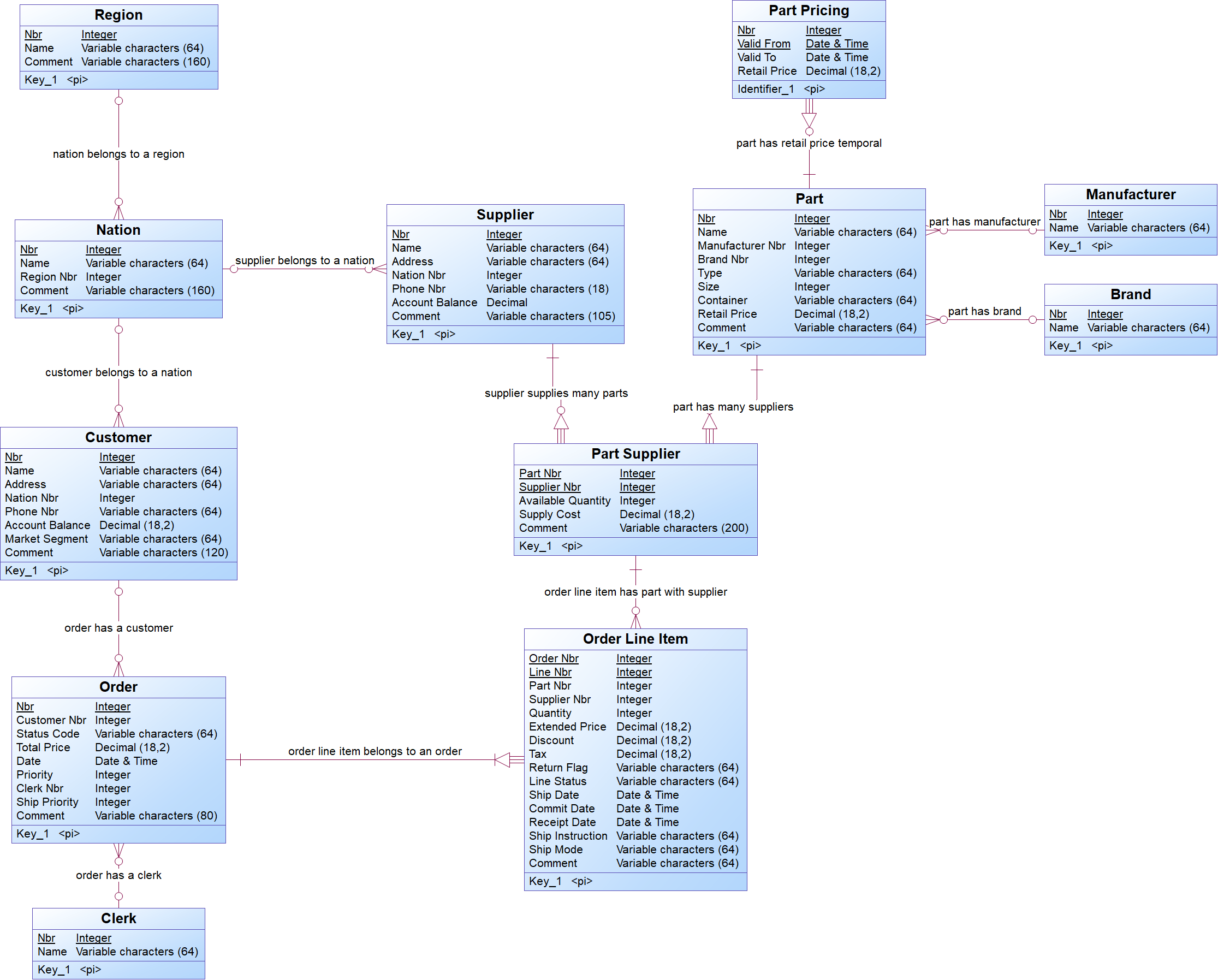
Before you begin
Before you create a technical staging model for a specific data source, it is important to get information about how data will be the delivered, i.e. how many tables will be used (data may be spread in several tables or just one table will be delivered) and the name of the columns of each table.
It is advisable that you also understand the business requirements and how they relate with the data delivery structure. Based on this information, you can identify data transformation operations that could be implemented in the technical staging model. Whenever possible, apply data transformations in the technical layer to facilitate the mappings between the logical validation model and the technical staging model. In general, data transformations make data more readily useful and closer to the business requirements.
The table below shows different types of data transformation operations.
| Operation | Definition |
|---|---|
| Data cleansing | Validates and corrects data by removing duplicates and missing values, correcting typos and transforming it into the right format |
| Derivation | Computes simple cross-column values |
| Filtering | Filters data on the based on certain values |
| Joining | Connects data across tables |
| Merging | Combines records from multiple tables based on a common identifier |
| Normalization | Splits a table in two or more tables |
| Pivoting | Turns row values into columns and vice-versa |
| Removing columns | Selects and removes columns that are not relevant |
| Splitting | Splits a single column into multiple columns |
| Vectorization | Converts non-numerical data into arrays of numbers |
These data transformations are implemented in a technical staging model through the use of helpers or computed columns.
Step 1. Adding an empty model
To start building a technical staging model model, first you should create an empty technical staging model from a template, then the model will have all the necessary default settings. At any moment, you can perform a model check to verify if there are errors in the model.
Step 2. Creating entities and attributes
There are two common ways to create entities and attributes in a technical staging model. You can do reverse engineer from the source system or you can create entities and attributes manually based on the agreed data delivery structure.
{info}In PowerDesigner, an entity is called a
tableand an attribute is called acolumn.
For each table from the data delivery structure:
- Create an entity.
- Add one or more attributes to the new entity. Make sure that the
Codeof the attribute is identical to the column name in the source data.
{example} In our example, an entity is created for each one of the tables described in the data delivery structure.
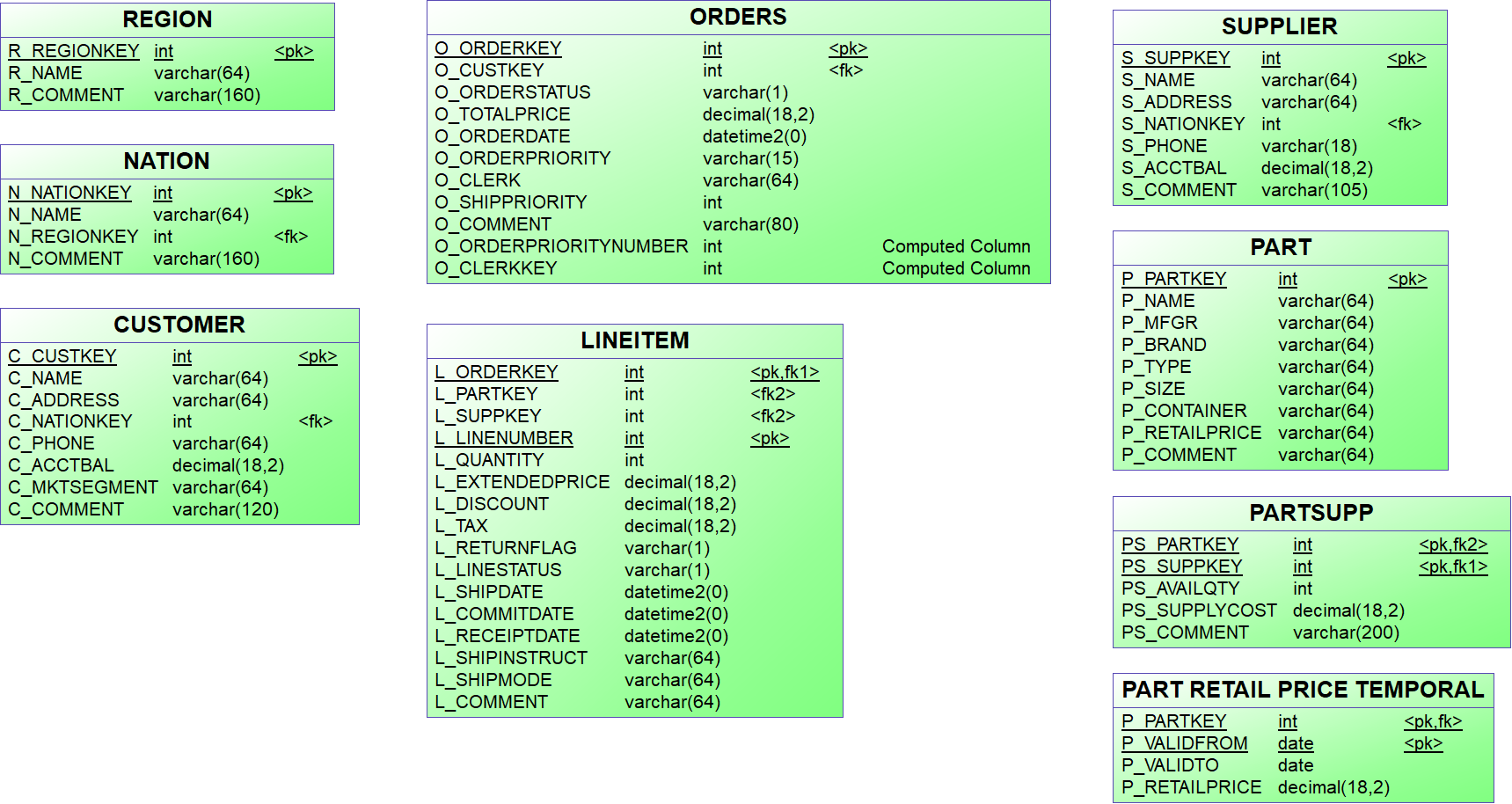
When you create entities and attributes for a technical staging model, make sure to follow the good practices
{warning} When the data type of the columns in the technical staging model does not match the data types of the delivered data then the loading process of the TSL fails. For example, if you supply the value 'Non-Applicable' to the column named
order dateandorder dateis typed as DATE, the loading will fail.
Step 3. Adding metadata
You can add extra metadata to the technical staging model to make it more user-friendly and also to improve the loading process. This extra metadata can be added in the form of primary keys and references.
Step 3.1. Adding a primary key
In the technical staging model it is optional to assign a primary key to an entity. However, it is a good practice to add a primary key to the entities in the TSM because this leads to a more user-friendly structure and to a quicker load process to the logical validation layer (LVL).
{info} Normally, an index is always created on the primary key. However, the i-refactory server does not automatically create a unique index for a primary key in a technical model. This is done to ensure that the data will be loaded even if the primary key contains duplicates.
The primary key is added only as part of the metadata and it is not implemented in the physical database. In addition, the i-refactory will not check if the primary key is unique or not-null when loading the data into a technical staging table. In the logical validation layer, the i-refactory will check all necessary constraints including the primary key.
{warning} Make sure that the order in which you check the composite primary key matches the order in the source data. An incorrect order of index data slows the performance in the TSL.
{example} The references and primary keys of the TPCH technical staging model are the same as the ones from the logical data model.
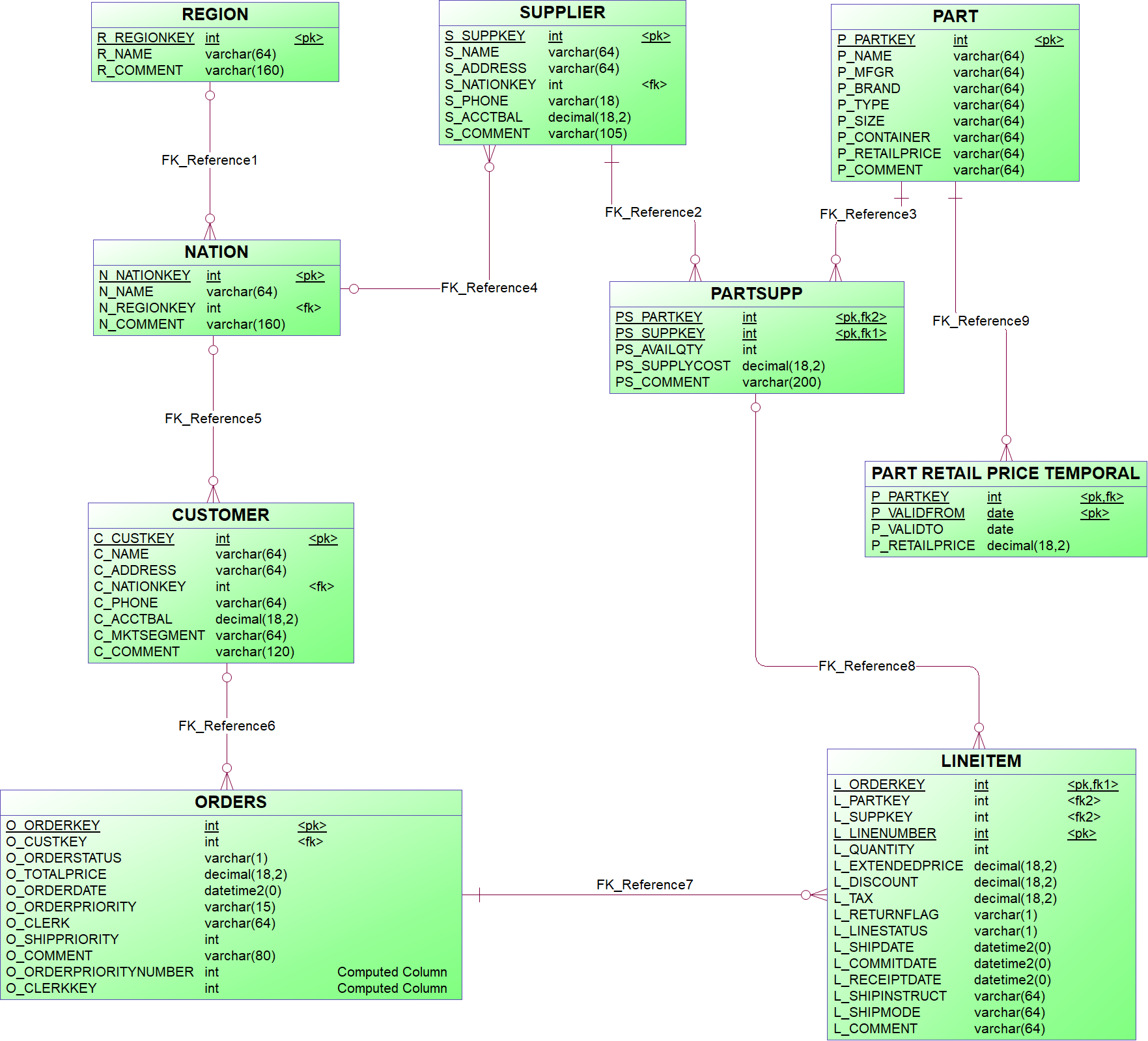
Step 3.2. Adding a reference
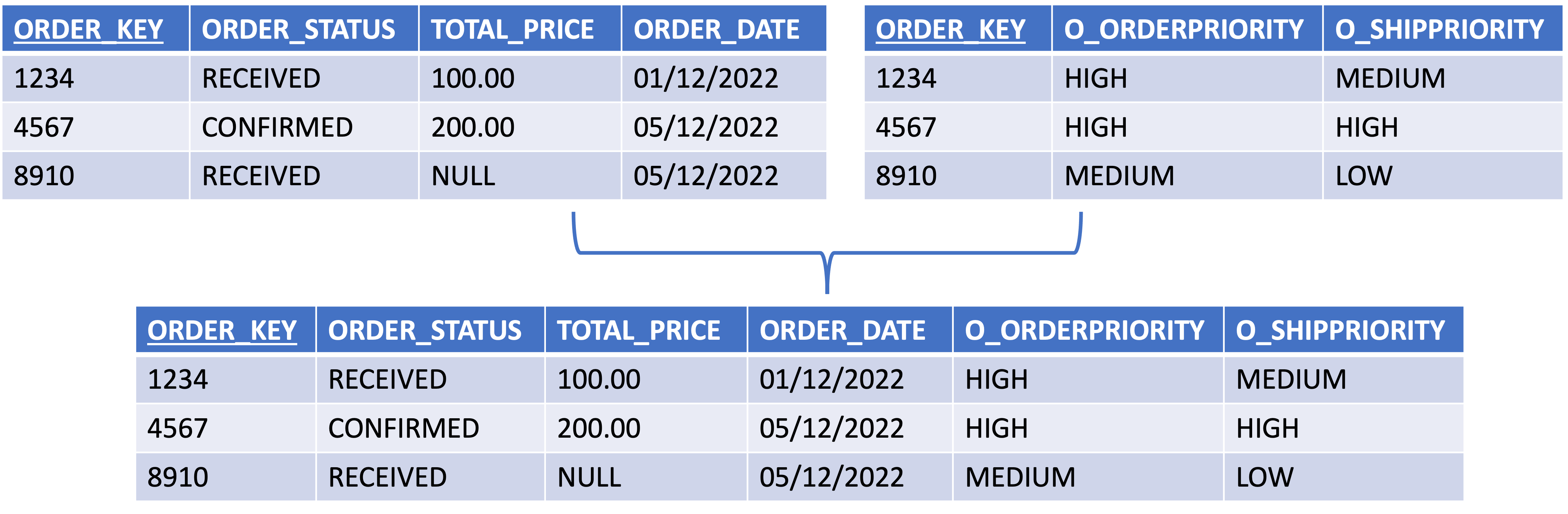
In the technical model, it is optional to create relationships between entities. This means that if the model contains foreign key relationships, these relationships are just stored as metadata and will not be implemented in the TSL database. However, it is a good practice to add a reference from the child entity to the parent entity of a relationship in the technical model. The parent entity is the one that is being referenced and the child entity is the one that makes the reference. We recommend adding relationships if you use helpers that connect two or more entities. The helper entity can generate a query that incorporates the foreign key relationship. Doing this, you can easily link multiple entities together in one helper.
{info} In PowerDesigner, a relationship is called
reference.
Step 4. Preparing for delta loads
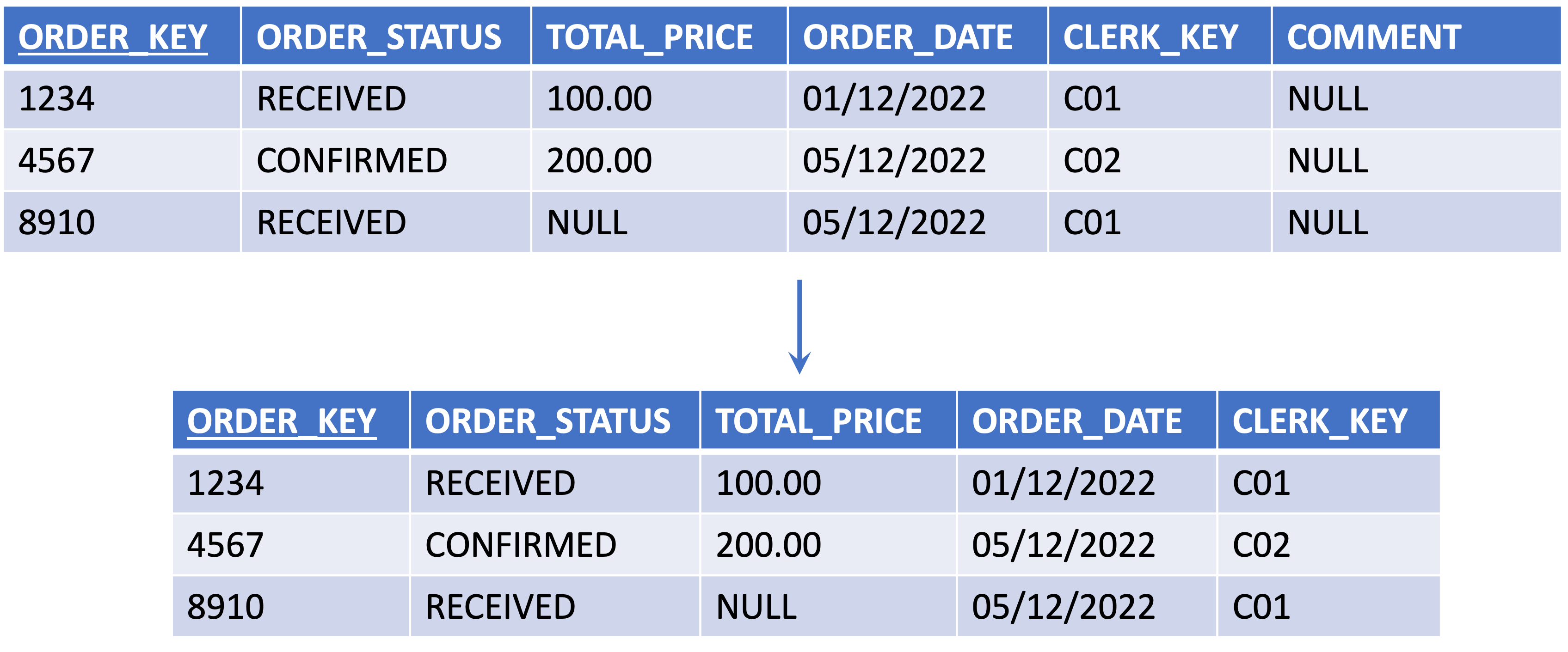
When a delta delivery is expected from a tenant, you need to make sure that each entity has an additional attribute to identify the records as new Inserts, Updates, or Deletes.
To prepare an entity for a delta load:
-
Add an attribute, called Source_Transaction_Indicator of type CHAR(1) optionally with enumeration I, U, and D.
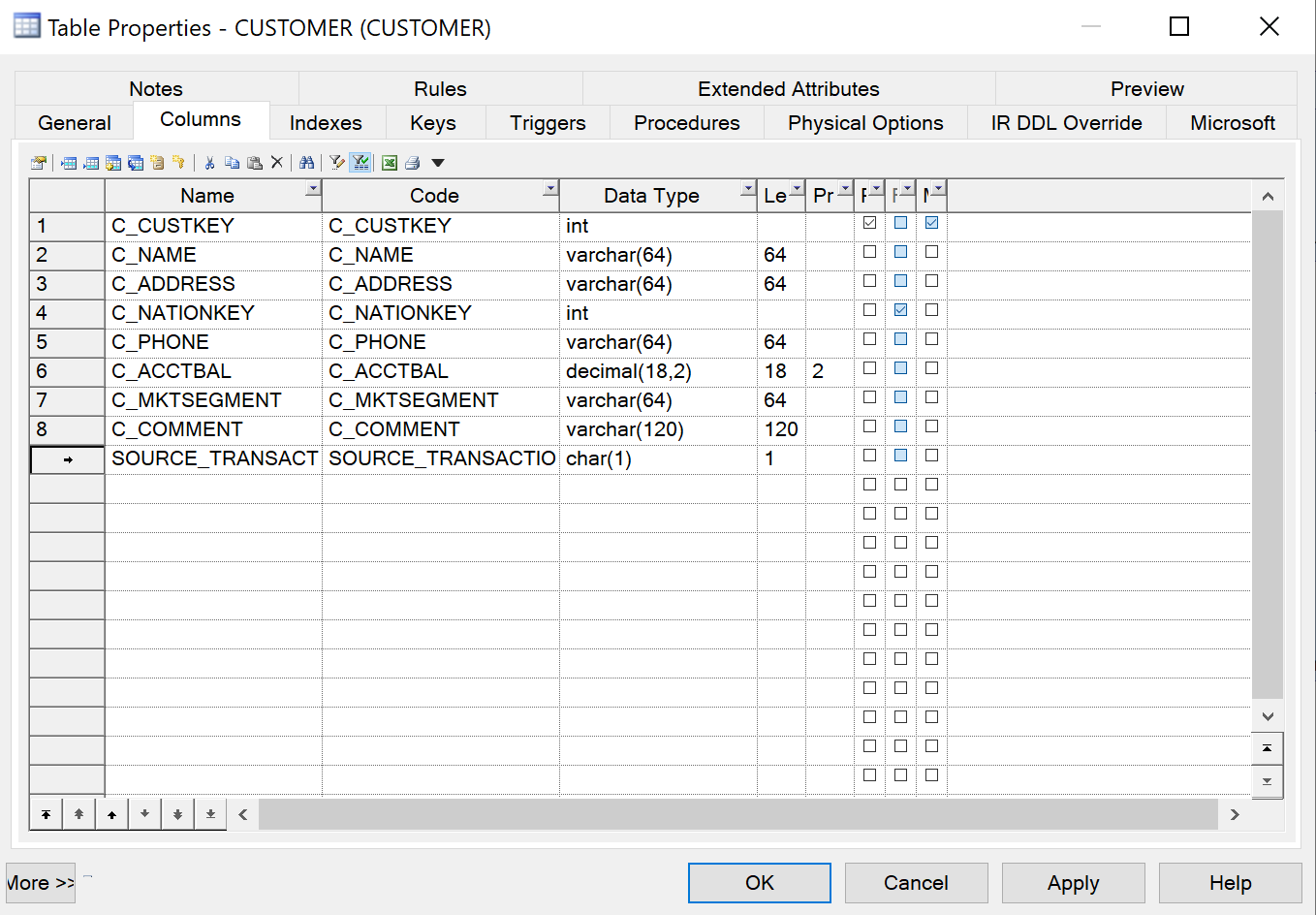
{info} The source transaction indicator is used for data retrieval. The data in this column should be populated with one of the following identifiers:
Ifor inserting new recordsUfor updating recordsDfor deleting records
Step 5. Adding helpers
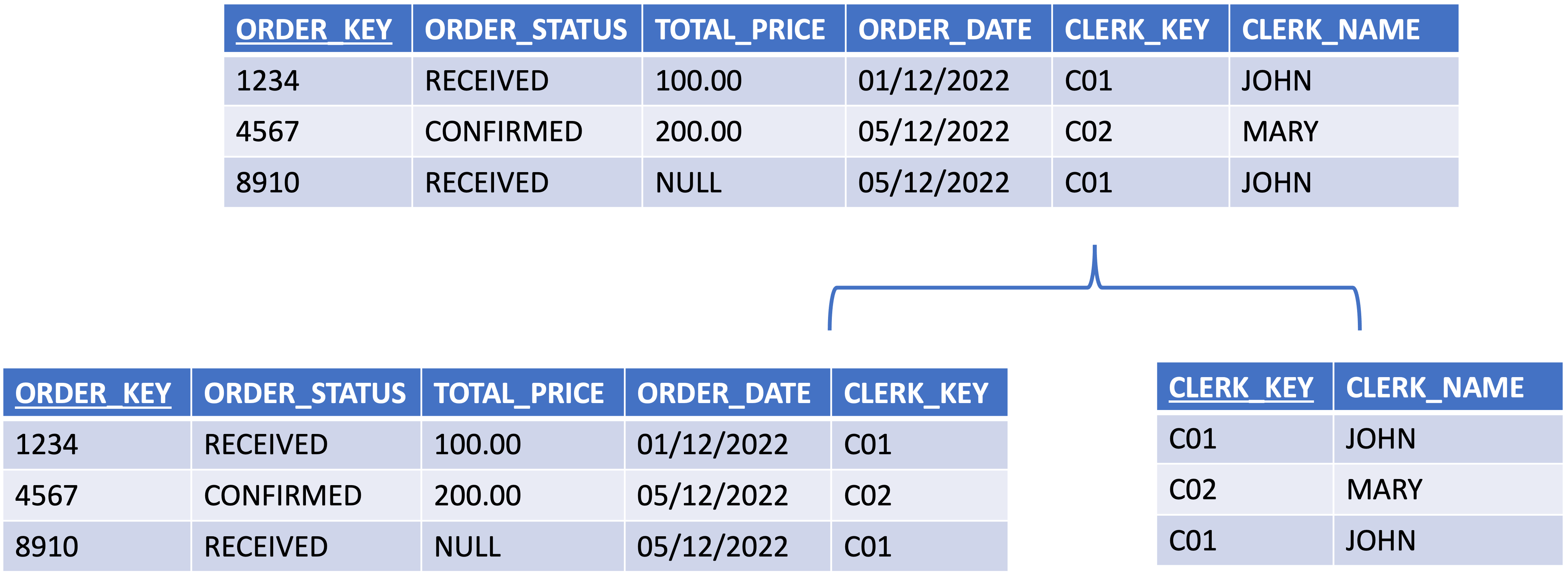
You can create a helper to perform a data transformation on the raw data coming from an external data supplier. A helper is implemented as a view in the database and can be used as the source of data for an entity in the logical validation model. In this case, there will be a mapping between the helper and the entity in the logical validation model.
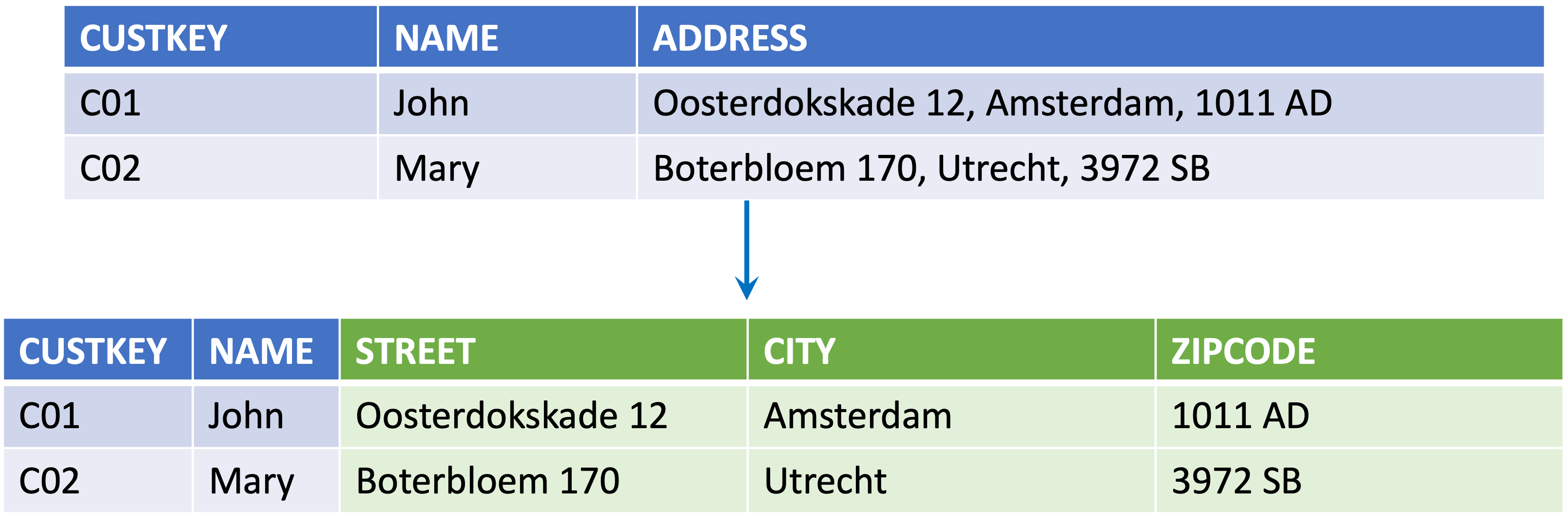
A helper can be useful when you have bad quality data coming from the data supplier and you need to apply a filter on this data or when you need to split a column value into separate columns or to concatenate different values into one new column.
{example} If the source system supplies shipping condition as "01 Road" where "01" is the identification of "Road", you can use a helper to split this information into two separate columns.
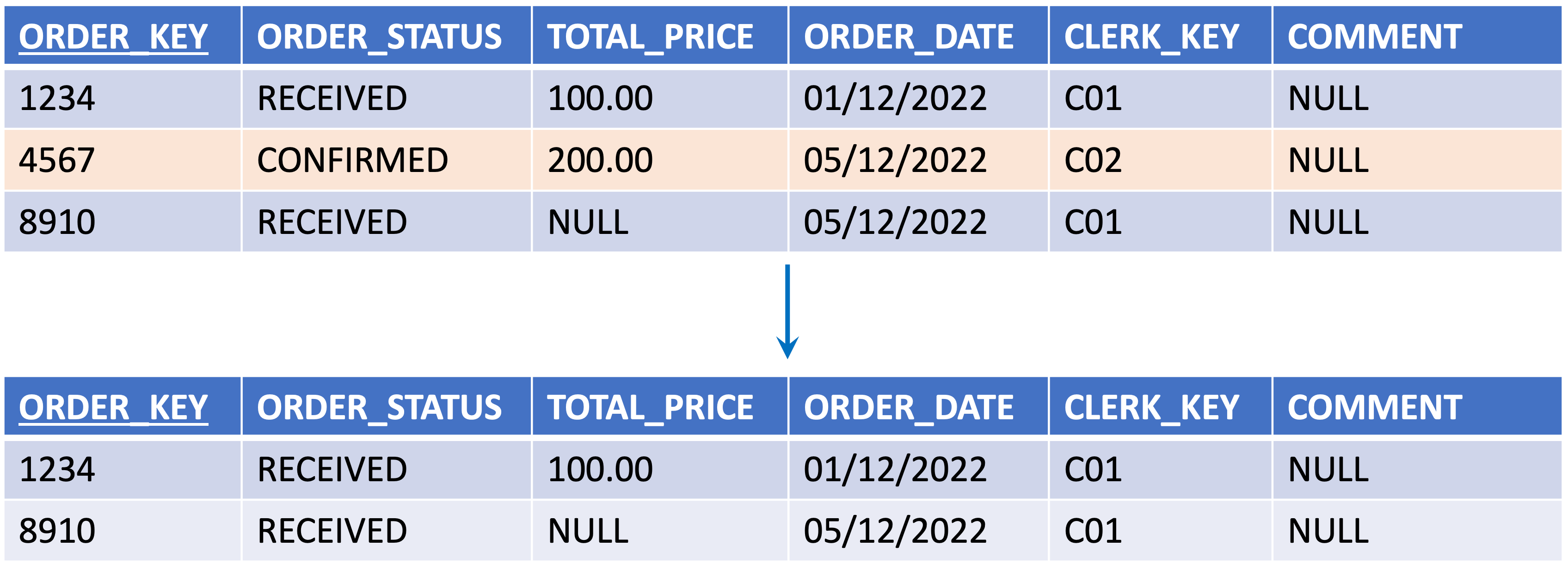
You can also use a helper to extract data from one entity in order to create several different entities. This normalization process will make the mapping between the technical model and the logical validation model more transparent.
{example} In our example the entity Part is delivered with information about Brand and Manufacturer. But, according to the LDM, instead of having just the entity 'Part' there should be individual entities for 'Brand' and 'Manufacturer'. The helper 'Part with derived columns' extracts manufacturer and brand identifiers (P_MFGRKEY and P_BRANDKEY) from the attributes 'P_MFGR' and P_BRAND, respectively. This helper is used as the source data for the entities Brand and Manufacturer in the LVM.
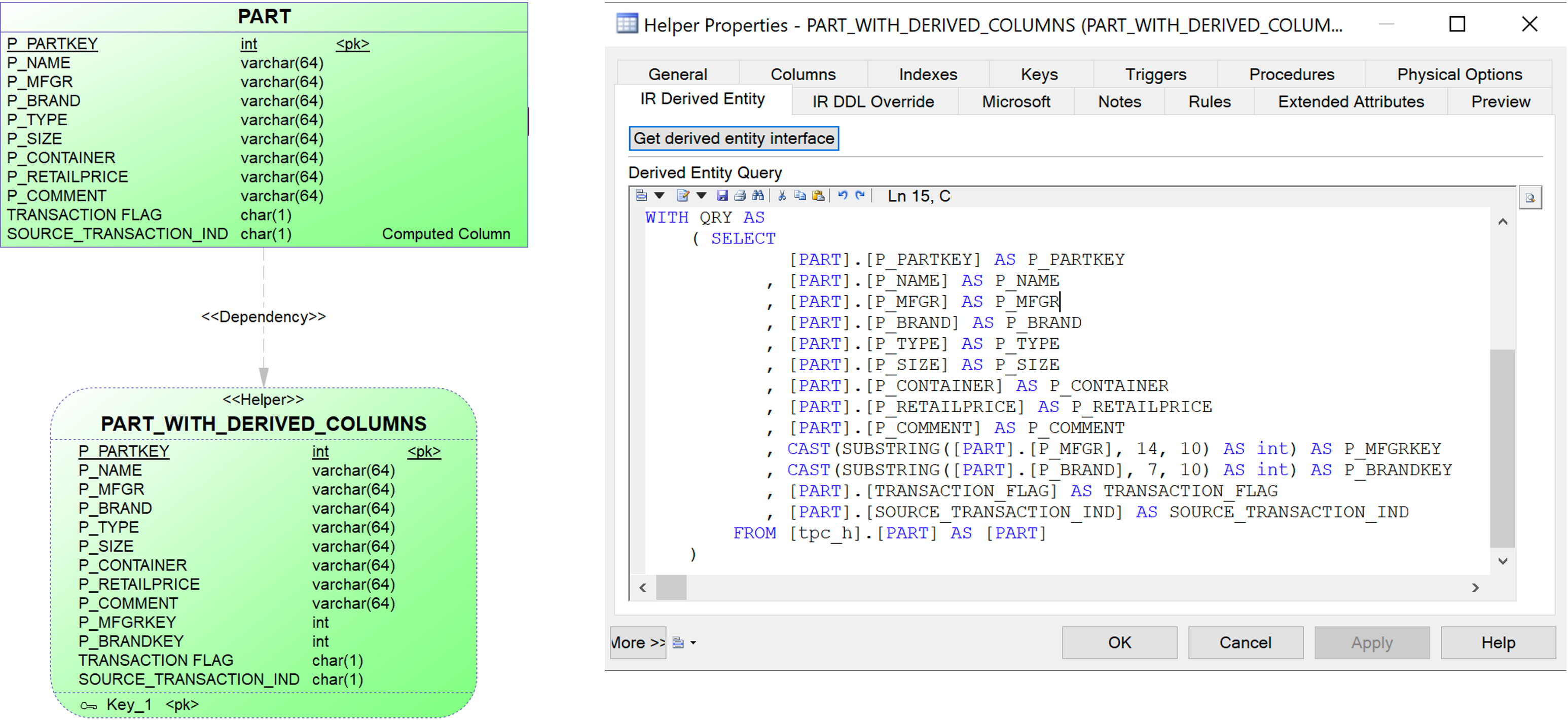
{example} According to the LDM, the business wants to have direct access to the the current price of parts. The helper 'Part with current price' extracts this information from the entity Part and it is used as the source data for the entity 'Part Pricing' in the LVM.
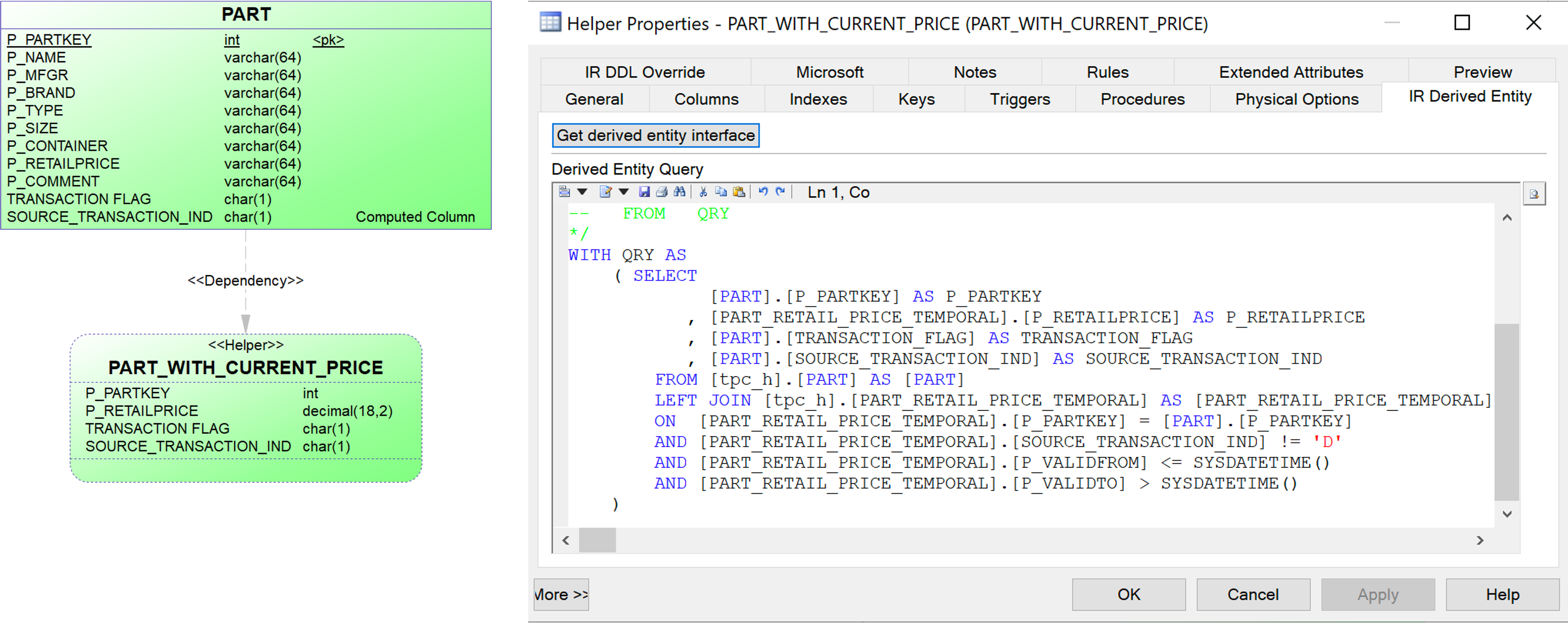
{tip} When you have a helper that joins tables, you can also add an index to speed up the process.
Step 6. Adding computed columns
Adding a computed column is supported and helps to perform computations or data improvement on record level. Nevertheless, we advise the use of a helper instead of a computed column..
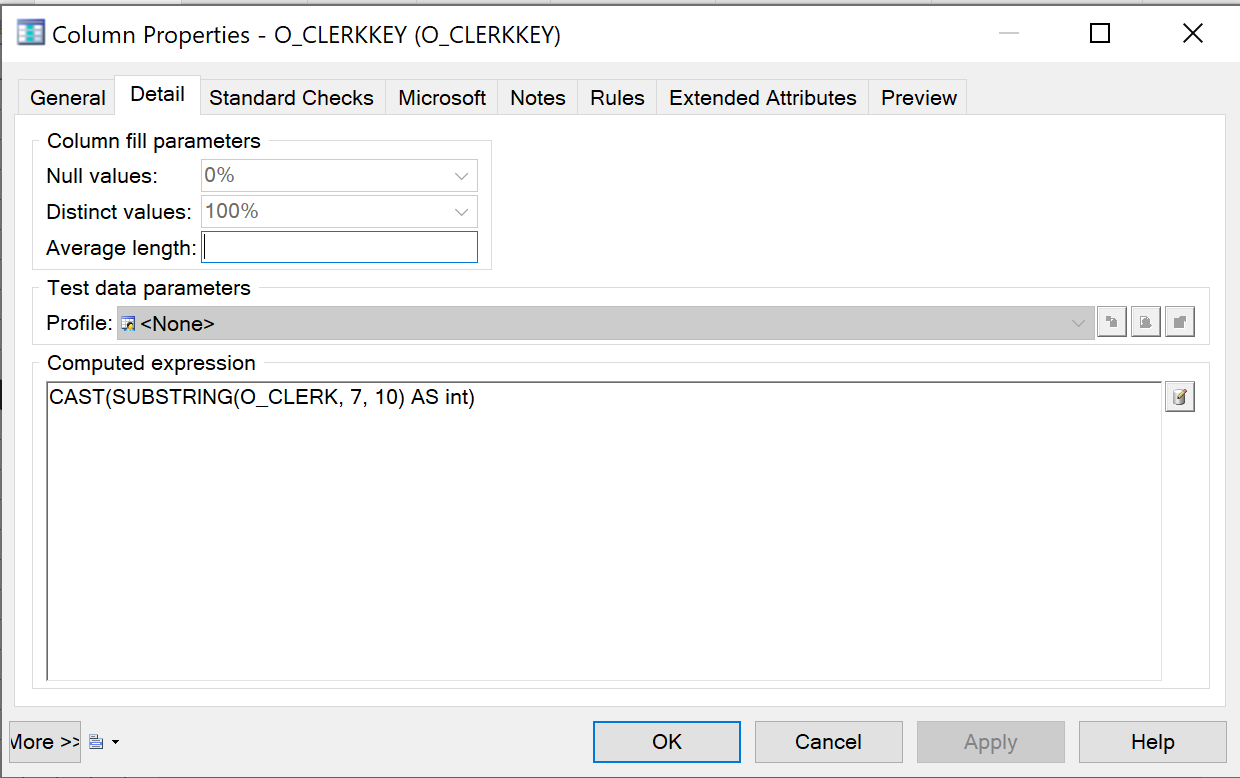
You can add a computed column to an entity in the technical staging model to store the results of data derivations. The expression used must be compliant with the database that executes this expression.
{example} A computed column is added to the entity Order to derive the priority number from O_ORDERPRIORITY into the new (computed) attribute O_ORDERPRIORITYNUMBER.
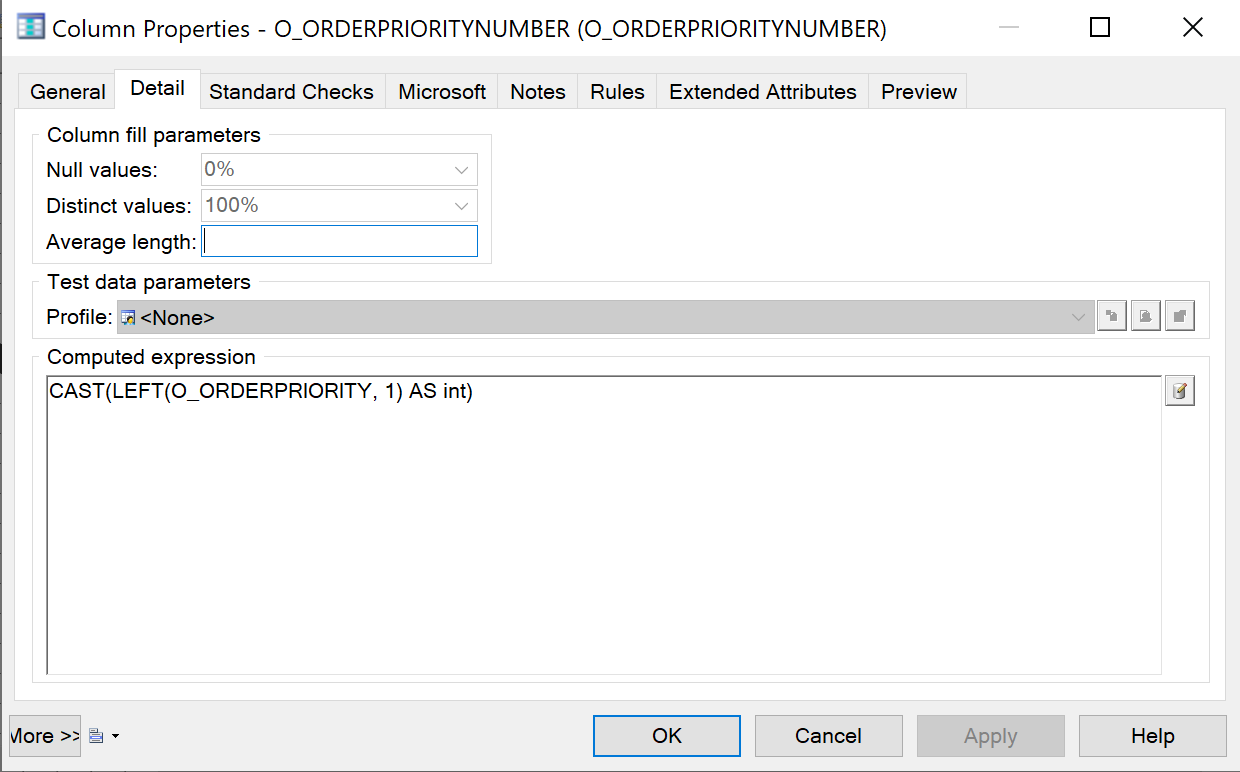
{example} A computed column is added to the entity Order to derive the number that identifies the clerk from the original supplied attribute O_CLERK into a new (computed) attribute O_CLERKNUMBER.