Setup SQL Server
In this section we will guide you through the setup and configuration of the SQL Server objects required for the i-refactory metadata repository. You will also find the prerequisites for the other logical data domains as well. The Solution Overview briefly introduces the role of SQL Server and the logical data domains.
Before you begin
Before you continue installing the SQL Server objects required for the i-refactory, please make sure:
- You have a SQL Server instance up and running.
- You have SQL Server Management Studio installed.
- You have access to the SQL Server instance with a DBA account.
Supported SQL Server Versions
The i-refactory server runs on SQL Server 2016, 2017, 2019 and 2022.
What is the i-refactory metadata repository?
In the i-refactory metadata repository we store the following information:
Data Definition Metadata: Facts regarding data models such as entities, attributes, relationships, constraints, ...Data Delivery Metadata: Facts regarding the creation of deliveries, the state of a delivery, the detailed specifications of a delivery, occurred constraint violations, ...Data Logistics Metadata: Facts regarding the execution of tasks to process a delivery.
On top of the fact store we've created access views with which you can easily retrieve the metadata information without having to know how the physical data is stored.
The i-refactory metadata repository is implemented as an immutable fact store which means we never update or remove metadata. The metadata is completely versioned. This allows for time travelling and auditability regarding the creation and changes of metadata data.
Storage requirements
The size of the i-refactory metadata repository in terms of disk storage depends on the number of daily executed deliveries and the number of data models created. Due to the nature of the immutability of the fact store the total disk size in time will grow.
Typically, the total storage in time requires several Gibabytes. As a rule of thumb, executing 1.000 tasks requires approximately 1 Megabyte of storage.
Step 1 - Unpack SQL Server folder
From the provided installation zip file unpack the folder i-refactory-sqlsever to a location where you are able to access the contents of this folder.
We will refer to this install folder in the next sections as I-REFACTORY-SQLSERVER-PATH.
Step 2 - Connect to your SQL Server instance
We recommend connecting to your SQL Server Instance with SQL Server Management Studio. Connect to your SQL Server instance with a DBA account.
If you don't have SQL Server Management Studio you at least should have a tool with which you can connect to your SQL Server instance and are allowed to execute SQLCMD script.
Step 3 - Create a database
Create a database in your SQL Server instance for the i-refactory metadata repository. We recommend naming the database IREFACTORY.
{info} Use your company standard settings for creating a SQL Server database. Make sure your SQL Server collation is set to
Latin1_General_CS_AS. If not, specify this collation when creating the database.
CREATE DATABASE [<Your Database Name>]
<Your Default Settings>Change the following settings:
ALTER DATABASE [<Your Database Name>] SET TRUSTWORTHY ON
GO
ALTER DATABASE [<Your Database Name>] SET ALLOW_SNAPSHOT_ISOLATION ON
GO
ALTER DATABASE [<Your Database Name>] SET READ_COMMITTED_SNAPSHOT ON
GO
ALTER DATABASE [<Your Database Name>] SET QUOTED_IDENTIFIER ON
GO{warning} The i-refactory metadata repository database should be configured for
READ_COMMITTED_SNAPSHOT. Not doing so will block both readers and writers and most likely will result in deadlock errors more often. To learn more check the Microsoft docs regarding Transaction Locking and Row Versioning Guide.
It is highly recommended to enable automatic statistics gathering.
ALTER DATABASE [<Your Database Name>] SET AUTO_UPDATE_STATISTICS ONStep 4 - Execute the install script
The i-refactory metadata repository SQLServer objects will be created with an install script which can be found in I-REFACTORY-SQLSERVER-PATH.
The script doesn't drop or alter anything. It will create new objects. It is assumed that you are installing in a clean and empty database.
The script runs within a transaction. If a failure occurs during the install, the complete install is reversed with a rollback. Your session will be disconnected upon failure. You need to close the session and create a new one.
To run the installation execute the following steps.
-
Open install script:
In SQL Server Management Studio open the file
Install.sqlfromI-REFACTORY-SQLSERVER-PATH. -
Change query parameters:
Menu > Query > Specify Values for Query ParametersSet the value of the following parameters:
Install directory: set the value toI-REFACTORY-SQLSERVER-PATH.i-refactory database name: set the value to the name of the database you created or accept the default value.Value for high end dt: keep the default value.
-
Change query to SQLCMD modus:
Menu > Query > SQLCMD mode -
Execute the script:
Execute
The install script typically will finish within 60 seconds.
The messages tabpage logs the result of the installation:
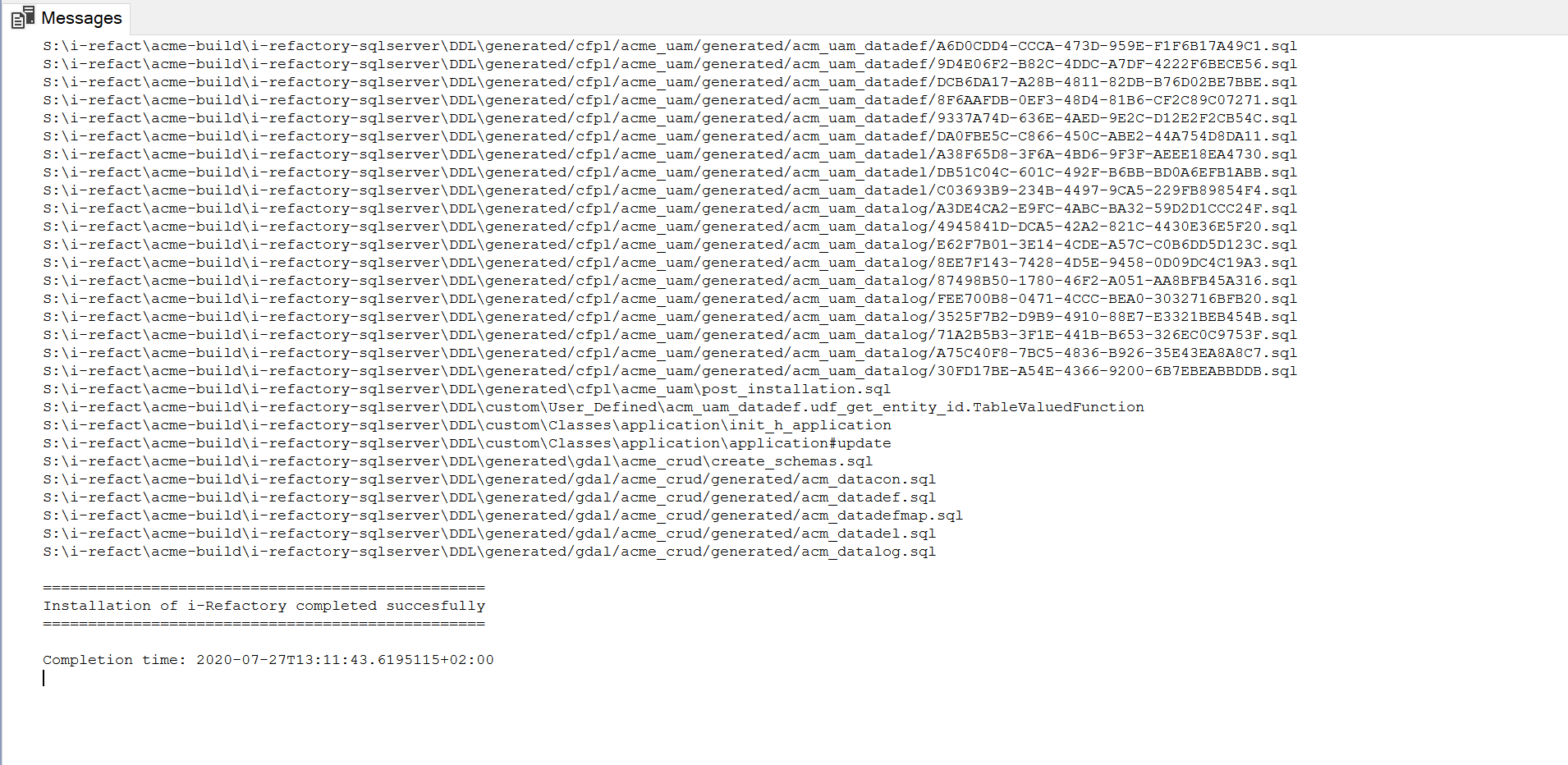
Step 5 - Create additional databases
Besides the storage of metadata we need to have storage locations for the data from external and internal data
We recommend to create at least 4 additional databases.
-
A technical staging database
In this database the tables are created for storing the raw data provided by the external data suppliers. The tables typically do not implement any constraints although optionally you can create indexes. The tables only contain data for a single data delivery. For each new delivery for a given data supplier the relevant tables should be truncated.
Instead of a single technical staging database you could create a technical staging database for each raw data supplier.
If you opt for a single technical staging database you should avoid naming conflicts between tables of different data suppliers by applying a unique schema (we call it a namespace) convention for each data supplier.
-
A logical validation database
In the logical validation database the raw data is transformed and stored in a logical format. In this database we also store intermediate results regarding the execution and validation of constraints. The tables stored in the logical validation database are buffered, a snapshot time is added to the primary key. Buffering allows for parallel execution of deliveries.
The same approach as for a technical database can be chosen for a logical validation database. You can opt to create only one database or a database for each external data supplier.
-
A facts database
As a rule of thumb, you only create a single fact database. In this database typically the facts are stored for each and every delivery and for each and every data supplier. The fact database is integrated over data sources.
{editorial} [EJ] Create reference to explanation of the fact store.
However, if data from external sources doesn't need to be integrated you could opt here as well to create a seperate database for each specific data source.
-
A data access database
In the data access database no physical data is stored, nor are any physical tables created. The database simply creates interfaces on the facts stored in the fact database. These interfaces are implemented as views, stored procedures and table valued functions.
The same approach as for a technical and logical validation can be chosen. You could create only a single data access database or several ones. Again care should be taken regarding possible naming conflicts on object types.
{info} Depending on the data volumes, number of concurrent users, ... the required SQL Server resources should be carefully sized regarding CPU, memory, data storage, temp storage. It is assumed that sufficient DBA experience is available to manage and configure a SQL Server instance and databases.
-
Step 1 - For each database you want to create.
CREATE DATABASE [<Your Database Name>] <Your Default Settings> -
Step 2 - Change the following settings:
ALTER DATABASE [<Your Database Name>] SET TRUSTWORTHY ON GO ALTER DATABASE [<Your Database Name>] SET ALLOW_SNAPSHOT_ISOLATION ON GO ALTER DATABASE [<Your Database Name>] SET READ_COMMITTED_SNAPSHOT ON GO ALTER DATABASE [<Your Database Name>] SET QUOTED_IDENTIFIER ON GO
{warning} The databases should be configured for
READ_COMMITTED_SNAPSHOT. Not doing so will block both readers and writers accessing the same data and will most likely result in deadlock errors more often. To learn more check the Microsoft docs regarding Transaction Locking and Row Versioning Guide.
Step 6 - Grant access to the metadata database
The i-refactory server needs to be able to connect to the SQL Server instance with a SQL Server login. To access to the i-refactory metadata repository, a user should be created for this login. This user should be granted specific access rights.
To create the login and a user with proper access rights on the i-refactory metadata repository, execute the following steps:
-
Connect to SQL Server Management studio.
-
Copy / paste the script in a new query window.
:setvar APPLICATION_USER "<Application user name, string, i-refactory>" :setvar APPLICATION_USER_PASSWORD "<Application user password, string,>" :setvar IREFACTORY_DB "<i-refactory repository database name, string, IREFACTORY>" USE [master] IF NOT EXISTS(SELECT * FROM sys.server_principals WHERE name = '$(APPLICATION_USER)') BEGIN CREATE LOGIN [$(APPLICATION_USER)] WITH PASSWORD=N'$(APPLICATION_USER_PASSWORD)', DEFAULT_DATABASE=[$(IREFACTORY_DB)], CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF GRANT VIEW SERVER STATE TO [$(APPLICATION_USER)]; END IF CAST(SERVERPROPERTY('productmajorversion') AS INTEGER) > 14 BEGIN -- SQLServer 2019 and higher support for loading CSV files with BULK INSERT requires additional GRANT. -- Note: this is not supported on SQLServer on Linux. GRANT ADMINISTER BULK OPERATIONS TO [$(APPLICATION_USER)]; END IF CAST(SERVERPROPERTY('productmajorversion') AS INTEGER) > 15 -- SQLServer 2022 and higher include additional security controls and therefore require additional GRANT. GRANT VIEW DATABASE PERFORMANCE STATE TO [$(APPLICATION_USER)]; END USE [$(IREFACTORY_DB)] IF NOT EXISTS(SELECT * FROM sys.database_principals WHERE name = '$(APPLICATION_USER)') BEGIN CREATE USER [$(APPLICATION_USER)] FOR LOGIN [$(APPLICATION_USER)] ALTER ROLE [db_datareader] ADD MEMBER [$(APPLICATION_USER)] ALTER ROLE [db_datawriter] ADD MEMBER [$(APPLICATION_USER)] ALTER ROLE [db_ddladmin] ADD MEMBER [$(APPLICATION_USER)] GRANT EXECUTE TO [$(APPLICATION_USER)]; END -
Change query parameters.
Menu > Query > Specify Values for Query ParametersSet the value of the following parameters:
Application username: change the value or accept the default.Application user password: enter a password.i-refactory repository database name: change the value or accept the default.
-
Change query to SQLCMD modus.
Menu > Query > SQLCMD mode -
Execute the script.
Execute
Step 7 - Grant access to the other databases
For each database you've created in Step 5: Create additonal databases, the i-refactory server needs to have proper access. We need to create a SQL Server user for each of these database with the proper access rights. We will use the login account created in Step 6 to create a user in each of the databases.
-
Connect to SQL Server Management studio.
-
Copy / paste the script in a new query window.
:setvar APPLICATION_USER "<Application user name, string, i-refactory>" :setvar DB "<Database name, string,>" USE [$(DB)] IF NOT EXISTS(SELECT * FROM sys.database_principals WHERE name = '$(APPLICATION_USER)') BEGIN CREATE USER [$(APPLICATION_USER)] FOR LOGIN [$(APPLICATION_USER)] ALTER ROLE [db_datareader] ADD MEMBER [$(APPLICATION_USER)] ALTER ROLE [db_datawriter] ADD MEMBER [$(APPLICATION_USER)] ALTER ROLE [db_ddladmin] ADD MEMBER [$(APPLICATION_USER)] END -
Change query parameters.
Menu > Query > Specify Values for Query ParametersSet the value of the following parameters:
Application username: change the value or accept the default.Database name: set the name of the database.
-
Change query to SQLCMD modus.
Menu > Query > SQLCMD mode -
Execute the script.
Execute
Step 8 - Allow connecting to the SQL Server instance
- The SQL Server Instance should be configured to allow access with SQL Server and Windows Authentication model.
- Connecting to the SQL Server Instance over TCP/IP should be enabled. Check with your company regarding firewall settings or other blocking settings preventing you from connecting over TCP/IP.
{info} The i-refactory server should be able to connect to the SQL Server instance with a low latency network connection.
What's next
Start the installation of i-refactory server.
{info} If you are not directly involved in the installation of the other server components you should inform your peers regarding the SQL Server setup.
At least provide the following information:
Schema
A schema is a set of database objects, such as tables, views, triggers, stored procedures, etc. In some databases a schema is called a namespace. A schema always belongs to one database. However, a database may have one or multiple schema's. A database administrator (DBA) can set different user permissions for each schema.
Each database represents tables internally as <schema_name>.<table_name>, for example tpc_h.customer. A schema helps to distinguish between tables belonging to different data sources. For example, two tables in two schema's can share the same name: tpc_h.customer and complaints.customer.