Unified Anchor Modelling
With i-refactory you have the possibility to serve a mixture of OLTP and OLAP scenarios in a fully automated manner. In order to support these scenario's modelling concepts you need to balance availability versus quality. The Unified Anchor Modelling is an enhanced set of modelling patterns, evolved from Anchor Modelling and Data Vault. The modelling is closely aligned with the concepts of Fact Based Modelling.
We created the Unified Anchor modelling to specify the modelling construct of the Central Fact Layer. In order to be able to maintain full history, we split the business keys in Anchors and their context as Context. Context are functionally dependent (“belong to”) their Anchor. This context can consist of attributes describing the Anchor and/or relationships. This split is often referred to as ‘6th Normal Form’.
We keep track of existence for every Anchor: for each Business Key stored in the Anchor we track if that key was delivered in the last delivery. We assume that a business key is denoted as the primary key in a Logical Model.
All Anchors are ‘append only’: only new rows are added, a record in an Anchor will never be removed . By default we maintain history for all Context. Context can be logically or physically deleted.
Anchor: Independent Entity
An Independent Entity is an entity that implements an Anchor for a Business Key that ‘stands alone’ e.g. that does not contain a reference to another Entity.
An Independent Entity contains Business Key fields, that show up as alternate key (AK), and the primary key (PK) is it's surrogate key (ID).
{info} With the Logical Model as your main reference, an independent entity can be identified by the following rule:
- Entity has a primary key
- None of the primary keys are foreign keys
Examples in TPCH: Customer, Order and Clerk.
Meta data stored for an Independent Entity:
Audit ID- Process that created the recordEntity ID- Reference to the Data Definition Register to the entityExistence- Indicates whether or not the key value is found (exists) in the most recent load of the entityLatest Start Datetime- the datetime at which the related context was last modifiedLast Created Datetime= Last Existence Datetime - the datetime at which the anchor existed (existence = true) most recently.
Anchor: Dependent Entity
A Dependent Entity is an entity that implements an Anchor for a Business Key that ‘depends’ in its existence on another Entity.
A Dependent Entity contains Business Key fields of which at least one is a foreign key (FK). The Business Keys will show up as alternate key (AK), and the primary key (PK) is it's surrogate key (ID).
{info} With the Logical Model as your main reference, a dependent entity can be identified by the following rule:
- Entity has a primary key
- At least one of the primary keys are foreign keys
- The entity has a dependent relation to another entity
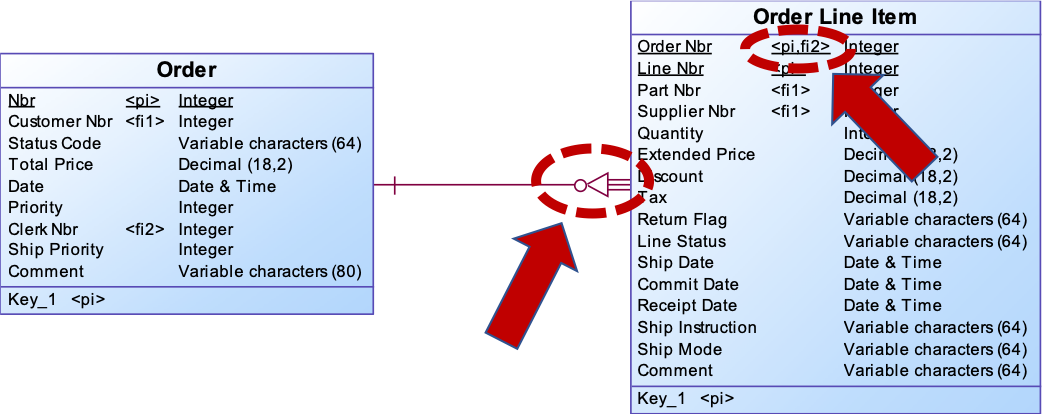
Examples in TPCH: Orderline Item and Part Supplier.
Meta data stored for a Dependent Entity equals to the metadata of an Independent Entity.
Context: Standard Context Entity
Context provides Context to an Anchor Entity and contains:
- Attributes describing the Context
- Relationships to Anchors (even to the same Anchor Entity)
- Every record is linked to the Anchor (reference named ID) as part of the Primary Key of the Context Entity
- Every record in a Context Entity is ‘timestamped’ with a Start- and End Datetime
- The Start Datetime is part of the Primary Key
Examples in TPCH: Part Supplier S Properties and Order Line Item S Properties.
{info} A Context Entity will be populated of the Attributes and relationships that are not part of the primary key.
The attributes in an entity in the Logical Model can be split over multiple Context Entities. Reasons to split one logical model entity into multiple Context Entities:
- Multi Active or bi-temporal behavior.
- Split of immutable attributes.
- Separate identification and uniqueness validation for Alternate Keys (see later).
- Rate of change (avoid data duplication of stable data).
- Runtime / information logistic considerations: each table can only be loaded from one table.
- Or any other physical / implementational consideration.
Metadata stored for a Context Entity:
Start datetimeof the transaction timeline - the transaction datetime uniquely identifies each change in the context. For batch processing this date is provided as part of the metadata of a delivery. For transactional processing the time is set when the data is committed.End datetimeof the transaction timeline - this field will be end dated if the record is logically deleted or updated.Audit ID- Process that created the Entity.Entity ID- Reference to the Data Definition Register to the entity.Record Indicator- indicates whether a record is a New record (N), result of an update (A) or logical delete (R).

The example shown above shows that first record is a new Record (‘N’) to Anchor with ID = 1. The functional Value is ‘aap’. For the same Anchor (with ID = 1) there are two more updates performed. The functional value is changed to 'noot' followed by 'mies'. Both updates are marked as appended update (‘A’). Last record is still open because the End datetime is dated in the future. Records are logically closed by physically updating the end date with the datetime of the next record.
We only INSERT records, we deviate from this rule to:
- set end dates for transaction timeline in context entities
- set existence and update metadata of anchors entities
- support physical deletion of context and registration of physical deletion on the Anchor.
Context: Immutable Context Entity
Immutable Context is a Context Entity for which all attributes and relationships are ‘insert once’: once the context is provided, it will never change. By doing so no history will be maintained.
As soon as context is provided for an Anchor, its context won’t be updated even if (changed) content is delivered. No errors or warnings are shown. Only when an update is provided via a CRUD-transaction processing call, an error will be returned.
{warning} Be aware: Updates by sources are ignored when processing Immutable Context.
In a Logical Model it is not visible whether context is immutable or not. This information should be specified by a modeller in the Central Facts Layer.
An example of Immutable Context could be meter readings or strict bookkeeping systems that allow no updates on financial transactions and thus enforce a reverse transaction instead.
Context: Bi-temporal Context Entity
A Bi-Temporal context is a context extended with two additional columns to store a valid timeline: Valid Start Datetime and Valid End Datetime. The Valid Start Datetime is part of the primary key, hence the primary key of a Bi-Temporal context is a composite key consisting of three columns: id, ACM Start Datetime, Valid Start Datetime.
A Bi-Temporal context cannot be used to track the existence of a key, for this you need to add a standard context (possibly a "dummy" context without any context columns).
Context: Multi-Active Context Entity
Multi-Active Context is a Context Entity that contains a Multi Active (Versioning Key) extending the business key of the associated Anchor.
{info} Each Multi Active Business Key has its own context which is functional dependent from the business key in the Anchor extended by the Multi Active Business Key.
This implies that one business key can have multiple context records at the same time.
Example: a customer has multiple types of phone numbers. “Home”, “Work” and “Mobile”. We add a Multi Active Key “Phone Nbr Type”.
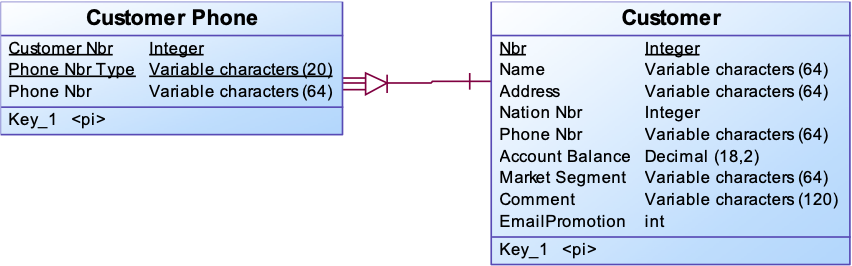
Let's assume your logical model specified the relation between customer and customer phone numbers as shown above. How can this be reflected in the CFL ?
- First alternative is to use
Multi-Active Context - Second alternative is to define a
Dependent Entityfor Customer Phone with it's own context
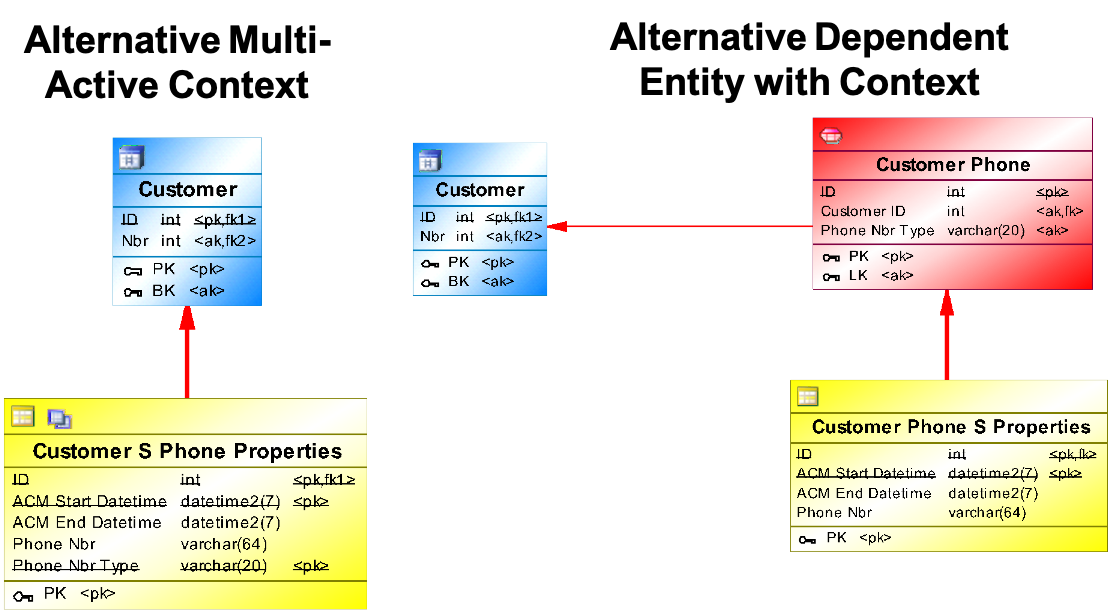
What alternative should you use?
- Benefit of an Anchor is that it can have its own contexts and can be referred to from other places in the model. However, an Anchor adds extra storage and extra joins.
- For an Anchor existence is stored as metadata. For a multi active key there is no existence stored.
{info} Rule of thumb: if we know for sure that there is and will never be context to the multi active key we can create a Multi Active Entity especially when performance and/or volume are important considerations. Choosing for an Anchor is more flexible but less efficient.
Context: Alternate Key Context Entity
Alternate Key Context is a Context Entity with an additional uniqueness constraint over it's alternate key columns.
{info} An Alternate Key Context only holds Alternate Keys that are treated as unique. If you combine Alternate Keys in one Context, the combination is treated as unique.
Relation: Foreign Key Link
A Foreign Key Link relates Anchor Context to another Anchor. It's a formalization of a foreign key relation as defined in your Logical DataModel.
The main benefits of Foreign Key Links are:
- simplification of the UAM Model construct,
- reduces number of joins by eliminating the use of a separate Dependent Entity as relation construct
- the loading pattern is determined automatically: you can load Context of Anchor A if the key as specified in the Foreign Key Link exists in Anchor B.
Relation: Super-Subtype Construct
A Subtype forms a subset of the business keys of its Supertype. A subtype is an (in)dependent entity on which existence is maintained. As an additional step, any insert to the subtype creates a record in the supertype.
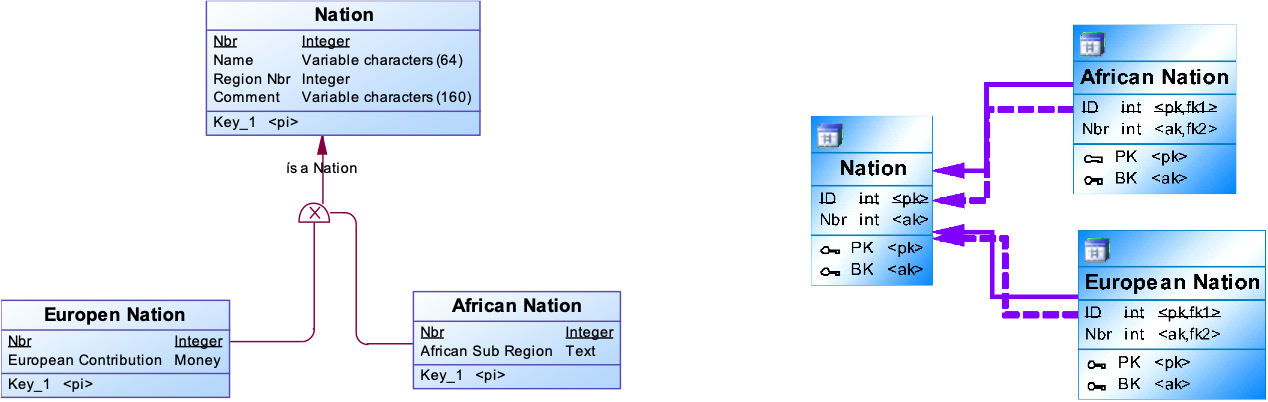
Subtypes are designated in your Logical Datamodel by the Subtype-symbol. The subtype construct can be Mutually exclusive and/or Complete. Check on these constraints should be part of the Logical Validation Model checks. No constraints are implemented in the CFL.
It is not necessary that every subtype is also physically implemented as a CFL subtype. Attributes of subtypes can be stored at their supertype. Formally a subtype describes a relation only.
Anchor: Generalization
A Generalization pattern defines a Supertype of more than one Anchor. This pattern generalize Anchors with different Business Keys.
Generalization Patterns are relevant for use cases when :
- You define relations to the Generalization Concept
- You maintain Context on the level of Generalization Concept as "common attributes"
Anchor: Key Root
This pattern is mainly used in a separate Concept Integration Model. A Key Root integrates entities of different Models that share the same Business Key. The KeyRoot is a technical construct that manages the integration within the Central Facts Layer. Since a Key Root only manages the integration based on keys, a Key Root cannot have any context.