Configure Interfaces
In this section we show how to configure the interfaces for each one of the i-refactory layers. Several parameters can be configured for the interface but also for each one of the entities that compose that interface. Here you can maintain the active (non archived) interfaces.
Disallow the update of an interface
It is possible to block the processing of deliveries on interface level. For instance: you could decide to postpone the update of all the entities just for a specific datamodel. To do this you can set the property updatable to false on the interface, just as you can do on Architecture Layer. The updatable conclusion displays the status of the update permission overall.
Change the setting of row counts
Row Count is used to provide statistics in processing deliveries through all our layers, calculate throughput times and determination of load-tactics from Logical Validation Layer to Central Fact Persistency Layer.
The setting of row counts can be entered on Architecture Layer level, Interface level or Entity level. The setting on Entity level has precedence over the setting on Interface level and the setting on Interface level has precedence over the setting on Architecture Layer level.
You can choose to set the row count to: Accurate, Approximate or None. The Approximate setting is the preferred setting. However, it is not 100% guaranteed that the result of the estimated row count actually reflects the row count of the number of rows in a table. Setting the row count to accurate however might have a severe impact on performance.
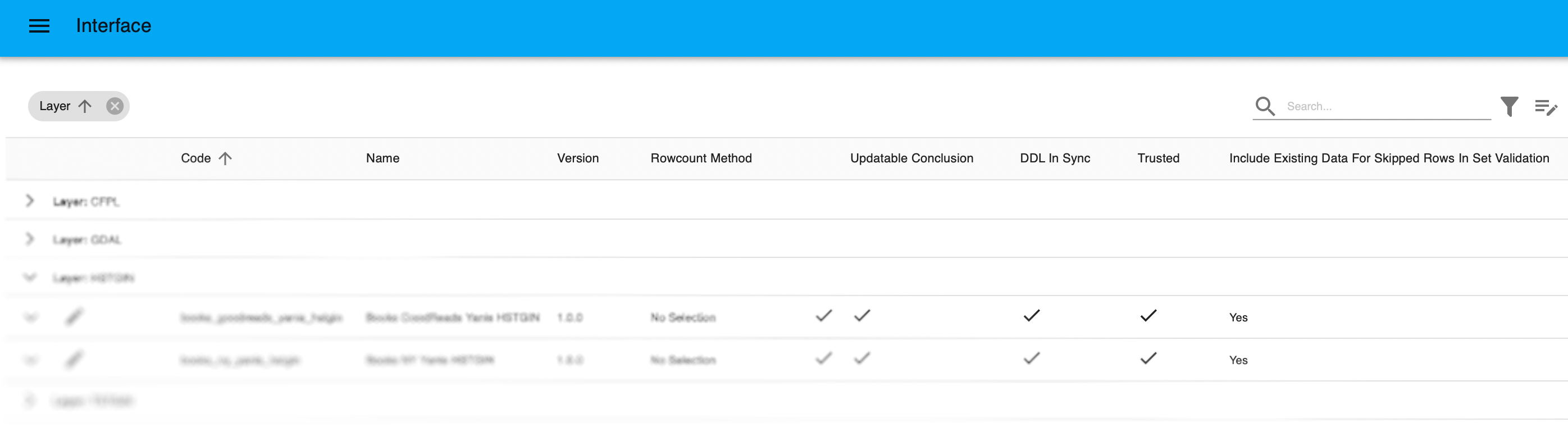
Trusted
The Trusted indicator is only valid for the Logical Validation Layer (HSTGIN).
The externally delivered data is historized in this layer in order to facilitate processing of new deliveries by having all relevant data:
a) to detect logical deletes,
b) to determine the exact delta that can be transfer to the Central Fact Repository layer and
c) to execute set based validations when deliveries contain deltas.
The historization of data in the Logical Validation Layer is optional. You are allowed to physically delete from the Logical Validation Layer. However, if you do not provide, in the next run, a Complete Delivery with Full datasets you could affect the processing of deliveries.
You uncheck the Trusted option to indicate that physical deletes of data in the LVL may have taken place and the processing of new deliveries cannot 100% rely (trust) on having enough statistics and data available to: detect logical deletes, determine the exact delta and execute set based validations.
As soon as a Complete Delivery with full datasets has been processed, you can switch the setting back to Trusted.
Include Existing Data For Skipped Rows In Set Validation
In the situation that rows of a delivery are rejected for basic constraints, by default the i-refactory tries to fetch the known data of these rejected rows from previous deliveries. This data is then used to perform set validations on rows in the current delivery that did not get rejected.
With the option includeExistingDataForSkippedRowsInSetValidation this default behavior can be changed for deliveries on this interface in the Logical Validation Layer (HSTGIN). If this flag is set to 'NO' the i-refactory will not fetch the data of skipped rows for set validation. The default value is 'YES'
This setting can be overriden on a Delivery Agreement or on individual Delivery. A Delivery's setting takes precedence over both the Delivery Agreement and Interface.
Manage Entities
As a drop-down menu for each Interface, you can maintain settings for the related artefacts.
Entity
As part of the Entity sub-screen, all Entities related to the selected Interface are listed. Here you can update the setting for Row Count.
Helper Entity
As part of the Helper Entity sub-screen, all Helper Entities related to the selected Interface are listed. Here you can update the setting for Transactional Consistent Filter.
Base Entity
As part of the Base Entity sub-screen, all Entities that result in tables are listed. Here you can update the setting for Trusted when you selected an Interface as part of the Logical Validation layer.
Derived Entity
As part of the Derived Entity sub-screen, all Entities that are designed as end-point of a Helper Entity (or Business Rule Helper) are shown for information purpose only.
Transactional Consistent Filter
This filter is relevant for Helper Entities (also known as Business Rule Helpers) active in the Central Fact Repository layer. A Helper Entity can be set to use the LEAST or GREATEST transaction time. It is highly recommended to choose the same option for all Helper Entities in your model. The default setting is LEAST (Consistency).
Consistency versus Accuracy
To understand the workings of Least / Greatest one has to keep in mind that in the i-refactory transaction time should always go forward. Updating / inserting facts before an already existing transaction time is not allowed.
When we load data we keep track of the last transaction time with which an Entity is updated. When we need to execute a Helper Entity in a central facts model we calculate the transaction time to use from the source entities that provide data to the helper entity. This calculation uses the last transaction times with which the source entities of a helper were updated. If this calculated transaction time is less than or equal to the transaction time of the last time the helper was executed we skip execution of the helper otherwise the helper entity will be executed. The calculated transaction time will be used as the transaction time for each target entity that has the helper entity as the source. With this approach we can provide a consistent derivation of facts.
Note: keep in mind that there is a tremendous amount of freedom in the query definition of the business rule helper and how you construct the query also regarding the filtering on transaction time. However, we will always use the calculated transaction time when loading to the target entity (with a helper as source entity). When calculating the transaction time we support two flavors: LEAST | GREATEST | CURRENT TIME.
If you need to ensure full consistency for derived facts - which may result in missed updates - then you should choose LEAST. If you need to ensure maximal accuracy of the derived facts - which may result in transaction time inconsistencies - then you should choose GREATEST. If Current Time is chosen then the variable @time_consistent_transaction_dt will be set to the current time.
Least
If one of the source entities for the helper entity has no value for the last known transaction time (because there is no delivery yet for this entity) then the LEAST option will default to the minimal transaction time as stated in the server config file, which is 1900-01-01 for our default config. Otherwise the least transaction time of the last transaction update times of all the source entities will be the result value. If the outcome of least is the minimal transaction time (1900-01-01) then the helper will not be executed.
Greatest
If one of the source entities has never been delivered before the greatest value of the remaining source entities will be calculated. If at least one of the source entities is delivered, the helper entity will be executed once the calculated transaction time is later than the last used transaction time.
EXAMPLE - both options
To understand both options we create the following model. Models A, B, and C are integrated into model D using a business rule helper. Note this is an example based on different source models - if one uses a business rule helper within the same model then the same applies for the entities inside the model.
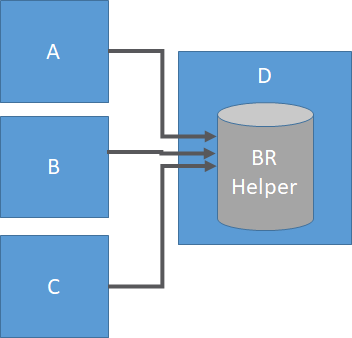
Least: delivers a read consistent set over all entities that are mapped to the business rule helper. When entities A, B, C are mapped to the business rule helper the least transaction time of the three is used for the helper.
Greatest: delivers a set based on the greatest transaction time over all entities that are mapped to the business rule helper. When entities A, B, C are mapped to the business rule helper the greatest transaction time of the three is used for the helper.
We now look at the following business rule helper queries, and determine the first moment the query returns data, and which transaction time is used, based on the query and the setting of the business rule helper.
- Query A : Inner join, every source must have attribute values at some point in time for the other sources
SELECT A INNER JOIN B INNER JOIN C- Query B : Outer join, every source may have attribute values at some point in time for the other sources
SELECT A LEFT OUTER JOIN B LEFT OUTER JOIN C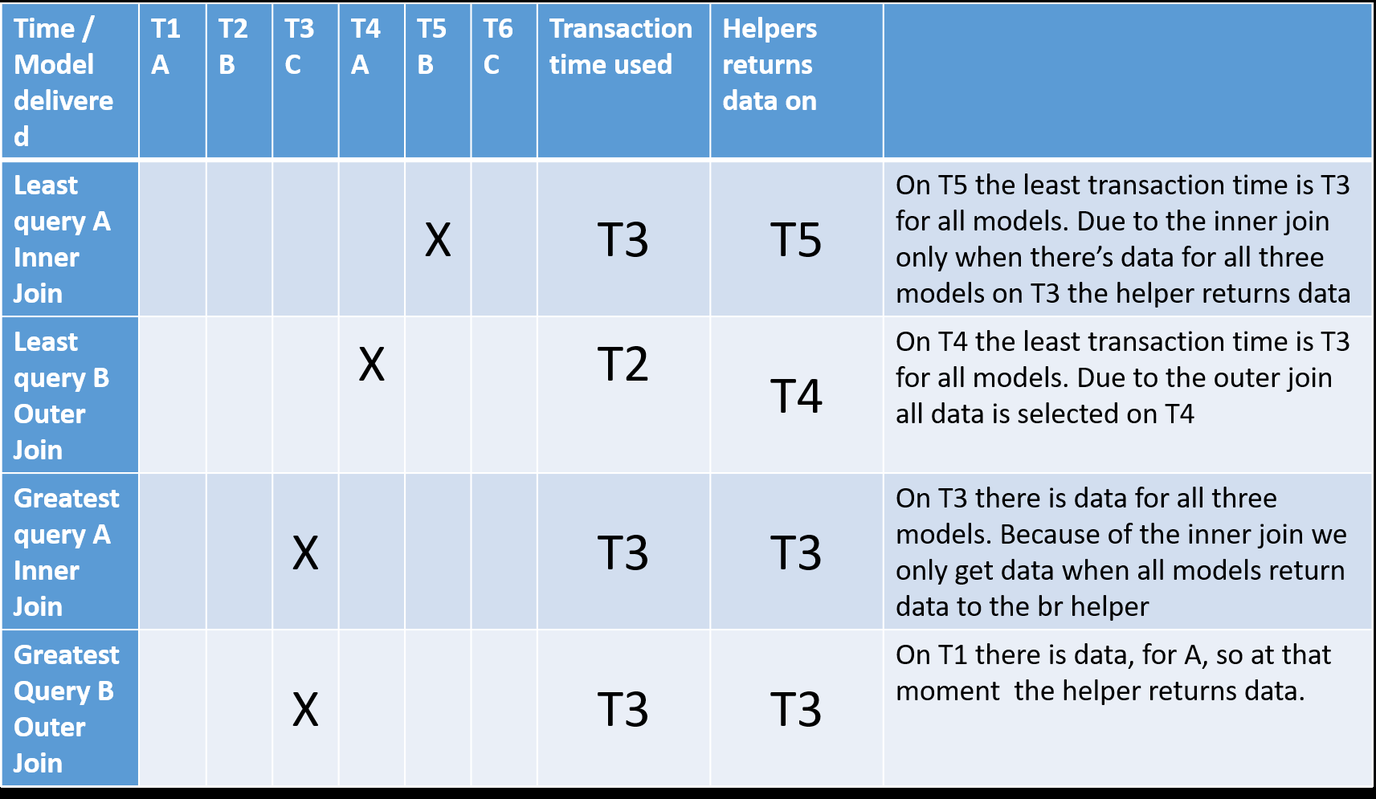
EXAMPLE - Greatest
An example will explain inconsistencies that can happen when GREATEST is chosen for some Business Rule Helper. Suppose the following order of deliveries and transaction times, and a helper that uses source data from models A, B and C.
| Model Delivery Order | Transaction Time |
|---|---|
| A | T1 |
| B | T2 |
| C | T3 |
| A | T5 |
| B | T6 |
| C | T4 |
When model C is updated at T3 the business rule helper will be executed with transaction time T3. When model A is updated at T5 the business rule helper will be executed with transaction time T5, and when model B is updated at T6 it will be executed with transaction time T6. But when model C is updated at T4 the business rule helper will not be executed. The input transaction times are now: T5, T6 and T4. The greatest value of these will result in T6. The rule was already executed with a transaction time of T6 so it will not be executed again. This behaviour may result in an inconsistent state of the derived fact, but it also has more up-to-date calculations. This shows the trade-off between consistency (Least) and accuracy (Greatest). Note that the inconsistency results from the fact that model C is updated at a later time than models A and B, but with an earlier transaction time. This situation will not happen if all models are always delivered with the current system time as their transaction time.
What's next?
- You can configure the architecture layers
- Check the overview