Reserve & Limit entity updates
The i-refactory server processes deliveries first in first out. Which means that transformation tasks of the earliest delivery will always have a higher priority than subsequent deliveries. Further, the number of transformation tasks the i-refactory processes in parallel is limited by the max concurrent entity updates setting on the Connection. If for example the first delivery in total contains 100 tasks to complete the delivery the scheduler will assign as many process slots as possible to finish this delivery as soon as possible. If however dependencies between processing tasks exist another delivery will be assigned one or more process slots until the max concurrenty entity updates slots are all granted.
To prevent deliveries from not getting any process slots you have the ability to set a maximum number of process slots on an agreement. Second, it is also possible to make a reservation for processing slots. When a reservation is made this number of processing slots is always available for processing a delivery. Making reservations therefore guarantees resources but at the cost of limiting other deliveries of consuming all the resources.
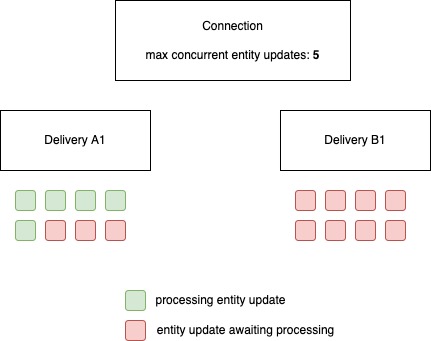
In total 16 processing tasks are created, 8 for delivery A1 and 8 for delivery B1. Delivery A1 is created before delivery B1. The maximum number of available slots is 5. Delivery A1 now tries to claim as much resources as possible. In this case there are no dependencies between the tasks for delivery A1. So 5 processing slots are assigned which will all be executed simultaneously. Once a task is finished the scheduler will check if it can run a task for delivery A1. If true again a slot is assigned for this new task. If however all the remaining tasks for delivery A1 have a dependency on not yet completed tasks the scheduler will check if a task for delivery B1 can be processed.
You can imagine that if delivery B1 somehow needs some priority in processing you want to limit the resources for delivery A1 or you want to make sure delivery B1 always has some available processing slots.
Maximum concurrent entity updates
You can restrict the number of concurrent entity updates to prevent deliveries from using all the available entity updates. You can set a maximum number of concurrent entity updates:
- For the connection
- For delivery agreements
- For deliveries
On an agreement you can set the maximum number of entity updates and you can set a default maximum number of entity updates. The latter setting will be used if you create a new delivery for this agreement and did not specify a maximum number of entity updates on the delivery. However, the maximum number of tasks for all the not yet completed deliveries can never exceed the maximum number of tasks as set on the connection or the agreement.
Reservations
The i-refactory allows you to reserve entity updates for deliveries and delivery agreements. By making reservations processing slots are always available for these deliveries. On a agreement you can set the maximum number of reservations and a default number of reservations. This behaviour works exactly the same as described above for the maximum number of entity updates. If a default is not set on the agreement nor on the delivery no processing slots will be reserved for the delivery.
Example 1:
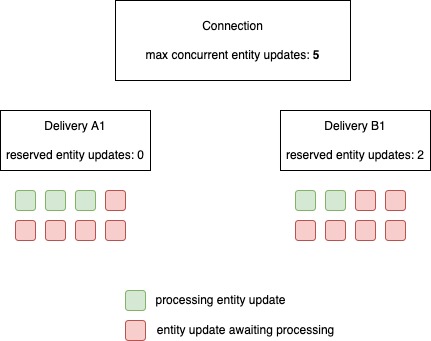
The example above shows 2 active deliveries. On the agreement nothing is set. Delivery A1 is created without reservations. Delivery B1 is created with 2 reservations. Delivery A1 will be limited to 3 processing slots (max of 5 on connections minus the 2 reserved sessions for delivery B).
The i-refactory starts to process delivery B, despite the oldest delivery not being finished yet.
Example 2:
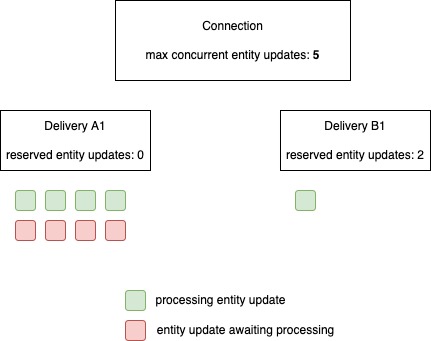
Delivery A is created without any reservations. The scheduler immediately assigns 4 processing slots to delivery A. Delivery B is created with 2 reservations. Delivery B now only gets one processing slot as only a max of 5 is available on the connection. When a task for delivery A1 completes these free slots will now be assigned for the remaining entities of delivery A1.
Example 3:
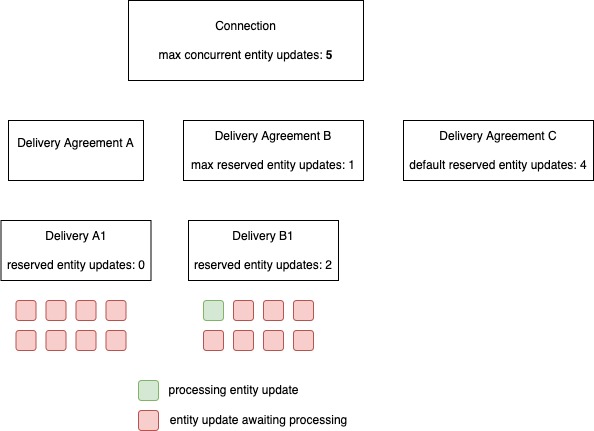
In this example 3 delivery agreements exist: A, B and C. Agreement A has no settings, B has set the max reserved entity updates to 1, and C has a default reservered entity updates of 4.
Delivery B1 is created with the delivery specific setting of reserved entity updates set to 2. The max however on agreement is set to 1. So delivery B will only get one slot reserved.
Deliver A1 is created without any specific settings. Although tasks exist for delivery A1 the scheduler will not grant any processing slots to delivery A1. This is due to the fact that agreement C has a default reservered entity updates of 4. These slots will be reserved for future deliveries.
Limiting reservations
If too many reserverations are made this might limit the throughput of the system. Not all processing slots will start processing tasks because the scheduler needs to reserve capacity for potential future deliveries.
On a connection and/or agreement a max reserved entity updates can be set.
If the sum of reservations exceeds the maximum, the i-refactory distributes the reservations according to the FIFO principle. Thus, it assigns reservations to deliveries in ascending order.
Example 4:
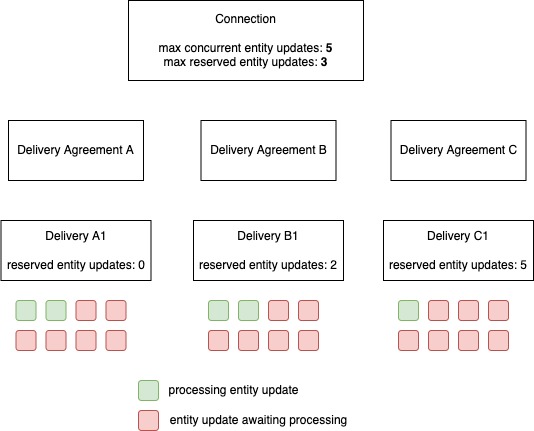
Although delivery B1 and C1 requested for 7 reserverd slots only 3 will be granted due the limitation set on connection.